27 基于 multi raft 的 shardkv 概述
前面的一个部分,我们完整实现了一个基于 raft,并且满足高可用、线性一致性的分布式 KV 存储系统。
这个新的部分会更进一步,我们会基于 raft 构建一个分片的分布式 KV。
一个分片(shard)指的是一个 Key/Value 数据集的一部分数据,比如,对一个有很多数据的 KV 存储系统中,所有以 ‘a’ 开头的 key 可以是一个分片,所有以 ‘b’ 开头的 key 可以是一个分片,当然这里只是简单举一个 shard 划分的例子,实际上划分数据的办法还有很多,最常见的是 Hash 和 Range。
我们为什么需要对数据进行分区?一个非常重要的原因是因为性能,在不分区的情况下,所有数据的读写请求都会在一个分片中,这在并发量较大的情况下可能存在一定的瓶颈。
如果对数据做了分区,那么不同分区之间的数据读写请求是可以并行的,这能够较大的提升 KV 系统的并发能力。
大致架构
我们这个部分需要完成的分片的分布式 KV 存储系统由两个主要的部分组成。首先是复制组(Replica Group),它指的是处理一个或多个 shard 的 KV 服务,通常是由一个 Raft 集群组成的,所以一个完整的分片分布式 KV 系统中一般存在多个 Replica Group,每个 Group 负责一部分 shard 的读写请求和数据存储,多个 Replica Group 的组合又叫做 multi raft。
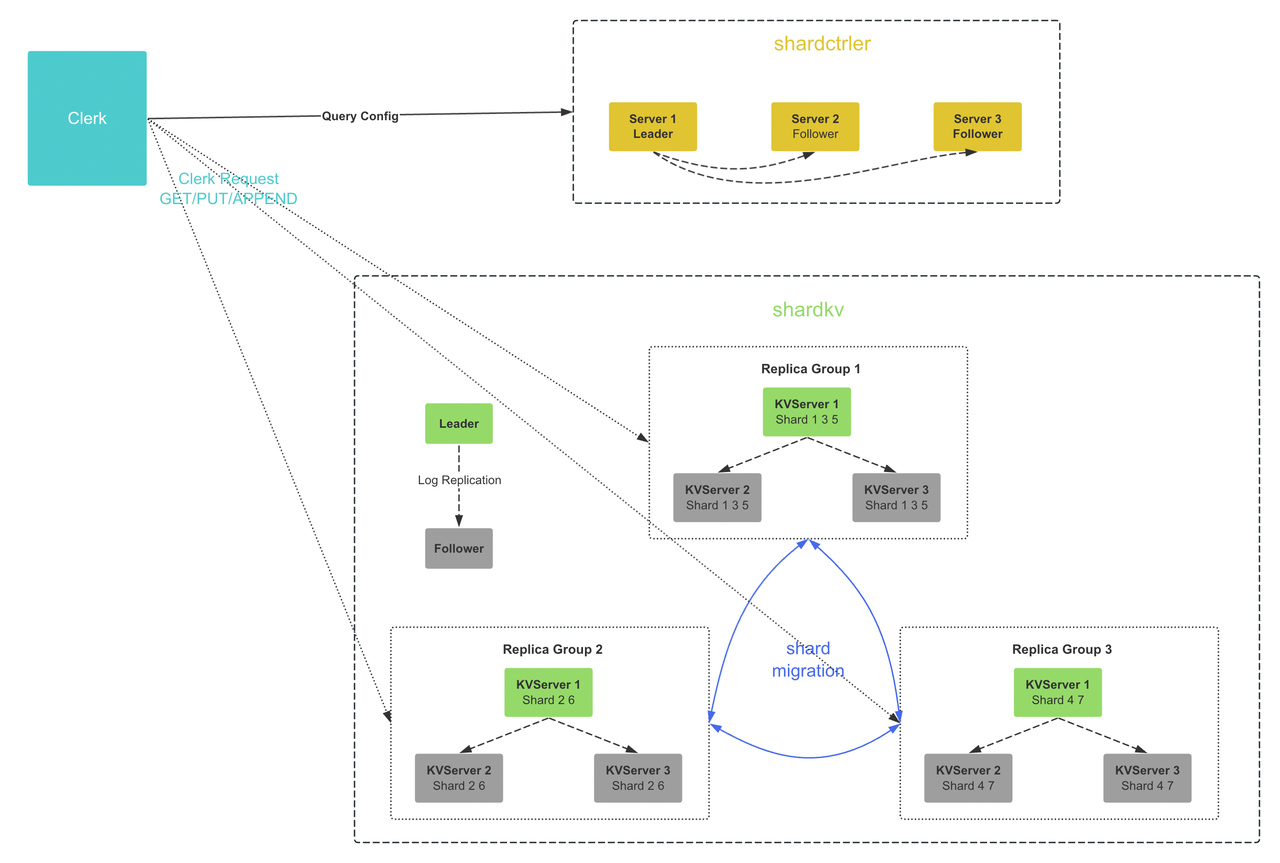
第二个组成部分是 “shard controller”,它主要是存储系统元数据,一般是一些配置信息,例如每个 Group 应该负责哪些 shard,这个配置信息是有可能发生变化的。客户端首先会从 shard controller 获取请求 key 所属的 Group,并且 Group 也会从 shard controller 中获取它应该负责哪些 shard。shard controller 也一般是会保证高可用,因为如果 shard controller 发生了单点故障,那么整个分布式 KV 系统就不可用了,因此 shard controller 也会使用 raft 进行状态同步。
我们实现的分片分布式系统需要能够将 shard 在不同的 Group 中进行迁移,为什么要这样做?
一个原因是负载均衡,比如一个 Group 有可能比其他的负责了更多 shard 的请求,导致其自身压力较大,因此我们需要将较多 shard 的 Group 移动到其他较少 shard 的 Group 中,让各个 Group 之间能够达到一个相对的均衡状态。
另一个原因是集群的变更,例如一个旧的 Group 有可能因为发生了故障而退出了整个集群,那么它负责的 shard 就应该转移到其他的 Group 中。还有一种情况是集群中加入了新的 Group,那么也需要将一些 shard 移动到这个新的 Group 中。
这一部分最主要的难点和挑战在于处理配置的变更,即 shard 到 Group 的映射关系。在一个 Group 的内部,所有 Group 内部的成员都必须要在处理请求和配置变更同时发生时保持一致。
例如,如果一个 Group 收到了配置变更的消息,指示它不能再负责一个 shard 了,而如果此时刚好有一个 Put 请求到这个 shard 上,那么此时 Group 内所有的副本都应该就 Put 请求应该是在配置变更之前还是之后生效而保持一致。如果是在之前生效的话,那么这个 Put 请求应该生效,并且 shard 新所属的 Group 能够看到这个 Put 的值,如果是之后生效的话,那么 Put 请求不应该成功,客户端需要向 shard 新的所属的 Group 重试请求。
这种情况的一种推荐的解决方案是将配置变更的请求也传到 raft 模块中进行状态同步,需要保证一个 shard 在同一时刻,只能被一个 Group 所负责。
配置变更也需要各个 Group 之间进行数据传输,比如一个 shard 在配置变更期间的所有权转移到了另一个 Group 中,那么一个 Group 就需要从原来的 Group 中获取这个 shard 的所有数据。
我们实现的分片分布式 KV 和生产环境中的分布式存储系统的大致架构是类似的,例如 BigTable、Spanner、HBase、TiKV 等等。但是实际的系统的细节会更加的复杂。
代码框架
shardctrler
在我们的课程当中,分片分布式 KV 系统的代码会像其架构一样,分为两个部分,一是 shard controller,这部分代码在目录 shardctrler 中。
这部分的大致逻辑和前一部分中实现的分布式 KV 类似,客户端以 Clerk 结构体进行维护:
1 | type Clerk struct { |
客户端这边有四个基础的方法 Query、Join、Leave、Move,表示集群配置的变更,shardctrler 需要处理这个变更,然后将配置信息存储起来。
服务端的处理逻辑和前面的分布式 KV 基本类似,并且由于配置信息数据一般会比较少,因此我们甚至不需要实现 snapshot 机制。
shardkv
另一个组成部分是在目录 shardkv 中,这里主要处理的是分布式 KV 的具体逻辑,客户端同样以 Clerk 结构体进行表示:
1 | type Clerk struct { |
可以看到 Clerk 相较于之前的多了一些额外的信息,包括 shardctrler、配置信息 Config 等。
客户端这边和之前一样,有三个基础的数据操作的方法 Get、Put、Append。
服务端的代码在 server.go 中,代码基础结构的定义和前一部分分布式 KV 比较类似。
1 | type ShardKV struct { |
参考资料
https://pdos.csail.mit.edu/6.824/labs/lab-shard.html
https://github.com/pingcap/blog-cn/blob/master/the-design-and-implementation-of-multi-raft.md
 微信
微信