func(rf *Raft) sendInstallSnapshot(server int, args *InstallSnapshotArgs, reply *InstallSnapshotReply) bool { ok := rf.peers[server].Call("Raft.InstallSnapshot", args, reply) return ok }
func(rf *Raft) installOnPeer(peer, term int, args *InstallSnapshotArgs) { reply := &InstallSnapshotReply{} ok := rf.sendInstallSnapshot(peer, args, reply)
rf.mu.Lock() defer rf.mu.Unlock() if !ok { LOG(rf.me, rf.currentTerm, DSnap, "-> S%d, Lost or crashed", peer) return } LOG(rf.me, rf.currentTerm, DDebug, "-> S%d, InstallSnap, Reply=%v", peer, reply.String())
// align the term if reply.Term > rf.currentTerm { rf.becomeFollowerLocked(reply.Term) return } // update the match and next if args.LastIncludedIndex > rf.matchIndex[peer] { // to avoid disorder reply rf.matchIndex[peer] = args.LastIncludedIndex rf.nextIndex[peer] = args.LastIncludedIndex + 1 }
// note: we need not try to update the commitIndex again, // because the snapshot included indexes are all committed }
reply.Term = rf.currentTerm // align the term if args.Term < rf.currentTerm { LOG(rf.me, rf.currentTerm, DSnap, "<- S%d, Reject Snap, Higher Term, T%d>T%d", args.LeaderId, rf.currentTerm, args.Term) return } if args.Term > rf.currentTerm { rf.becomeFollowerLocked(args.Term) }
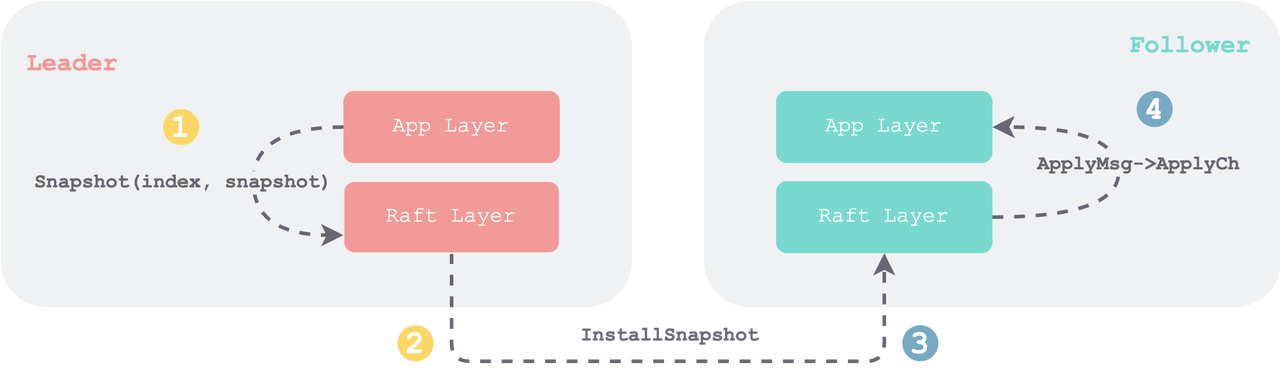
// check if it is a RPC which is out of order if rf.log.snapLastIdx >= args.LastIncludedIndex { LOG(rf.me, rf.currentTerm, DSnap, "<- S%d, Reject Snap, Already installed, Last: %d>=%d", args.LeaderId, rf.log.snapLastIdx, args.LastIncludedIndex) return } // install the snapshot rf.log.installSnapshot(args.LastIncludedIndex, args.LastIncludedTerm, args.Snapshot) rf.persistLocked() rf.snapPending = true rf.applyCond.Signal() }
// --- raft_log.go // isntall snapshot from the leader to the follower func(rl *RaftLog) installSnapshot(index, term int, snapshot []byte) { rl.snapLastIdx = index rl.snapLastTerm = term rl.snapshot = snapshot
// make a new log array // just discard all the local log, and use the leader's snapshot newLog := make([]LogEntry, 0, 1) newLog = append(newLog, LogEntry{ Term: rl.snapLastTerm, }) rl.tailLog = newLog }
 微信
微信